رشد سریع تکنولوژی و در پی آن افزایش حجم دادهها باعث شده است که بیشازپیش به زیرساختهای قدرتمند برای ذخیرهسازی و پردازش دادهها نیاز داشته باشیم. سرور اختصاصی برای بیگ دیتا یکی از مهمترین و مؤثرترین راهکارها برای مدیریت این حجم از داده است. یک سرور اختصاصی به دلیل داشتن پردازندههای چند هستهای، رم بالا و فضای ذخیرهسازی پرسرعت، میتواند بهخوبی فرایند پردازش دادههای حجیم را مدیریت کند. در کنار سختافزارهای قدرتمند، نرمافزارهایی مانند Hadoop و Apache Spark که برای پردازش دادههای زیاد طراحی شدهاند، فرایند تحلیل و پردازش داده در این سرورها را بهینهسازی میکنند. اگر قصد دارید بدانید سرور اختصاصی برای بیگ دیتا چیست، چه ویژگیهایی دارد و چگونه میتوان آن را بهینهسازی کرد تا انتهای این مطلب با ما همراه باشید.
بیگ دیتا چیست؟
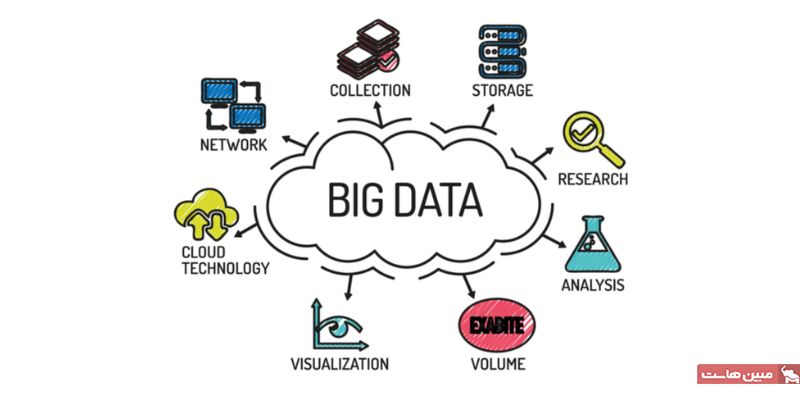
بیگ دیتا (Big Data) به مجموعهای از دادهها گفته میشود که از نظر حجم، سرعت پردازش و تنوع، بسیار بزرگتر از دادههایی هستند که سیستمهای معمولی قادر به پردازش و ذخیره آنها هستند. این دادهها به طور معمول به طور خودکار از منابع مختلف مانند اینترنت، دستگاههای هوشمند، شبکههای اجتماعی، و سایر سیستمهای دیجیتال جمعآوری میشوند.
ویژگیهای بیگ دیتا

ویژگیهای بیگ دیتا معمولاً به سه اصل کلی معروف هستند که به آنها “Three V” گفته میشود. اما علاوه بر این سه ویژگی، ویژگیهای دیگری نیز وجود دارند که به توضیح بهتر مفهوم بیگ دیتا کمک میکنند. در اینجا ویژگیهای اصلی بیگ دیتا را بررسی میکنیم:
حجم (Volume)
حجم دادهها در بیگ دیتا بسیار بزرگ است و میتواند به اندازه ترابایتها یا حتی پتابایتها برسد. این حجم بالا باعث میشود که ذخیرهسازی و پردازش این دادهها با استفاده از سیستمهای معمولی بسیار دشوار باشد.
سرعت (Velocity)
دادهها به طور مداوم و با سرعت بالا تولید و به روز میشوند. این ویژگی نشاندهنده نرخ تولید دادهها است. به عنوان مثال، شبکههای اجتماعی به سرعت اطلاعات جدید را منتشر میکنند و این سرعت بالا میتواند برای تحلیل و پردازش آنها به چالش تبدیل شود.
تنوع (Variety)
دادهها در بیگ دیتا از انواع مختلفی برخوردارند. این دادهها میتوانند ساختار یافته (مثل دادههای پایگاه دادهها) یا غیرساختار یافته (مثل متنها، تصاویر، ویدئوها، و صداها) باشند. تنوع دادهها نیازمند استفاده از تکنیکهای پیچیده برای پردازش و تحلیل آنها است.
برخی از ویژگیهای دیگر بیگ دیتا عبارتند از:
صحت (Veracity)
به کیفیت و دقت دادهها اشاره دارد. در بیگ دیتا، ممکن است دادهها نادرست، ناقص یا متناقض باشند. بنابراین، پردازش و تحلیل دادههای با کیفیت پایین میتواند نتایج نادرستی به دنبال داشته باشد.
ارزش (Value)
این ویژگی به میزان اطلاعات مفید و سودمندی که از دادههای بیگ دیتا استخراج میشود اشاره دارد. همه دادهها ارزش یکسانی ندارند و باید توانایی استخراج اطلاعات ارزشمند از دادهها را داشت.
پیوستگی (Variability)
اشاره به تغییرات در دادهها در طول زمان دارد. دادهها ممکن است به دلیل شرایط خاص یا تغییرات محیطی تغییر کنند. برای مثال، در شبکههای اجتماعی، نوع و میزان دادههای تولیدی ممکن است بسته به رویدادهای مختلف تغییر کند.
این ویژگیها نشان میدهند که بیگ دیتا با چالشهای خاص خود همراه است، اما در عین حال فرصتهای زیادی برای کشف الگوها، پیشبینیها و بهبود فرآیندهای مختلف فراهم میآورد.
سرور اختصاصی برای بیگ دیتا چیست؟

سرور اختصاصی برای بیگ دیتا به سروری فیزیکی و اختصاصی گفته میشود که به طور کامل برای پردازش، ذخیرهسازی و مدیریت دادههای بیگ دیتا اختصاص داده شده است و تمام منابع آن . این سرورها برای پردازش دادههایی که حجم زیاد، سرعت بالا و تنوع مختلف دارند طراحی شدهاند و امکانات و قدرت پردازشی بالایی دارند.
سرور اختصاصی برای بیگ دیتا چه ویژگیهایی دارد؟

در ادامه به ویژگیها و اهمیت سرورهای اختصاصی برای بیگ دیتا پرداخته میشود:
قدرت پردازشی بالا
سرورهای اختصاصی مانند سرور اختصاصی ایران برای بیگ دیتا نیاز به پردازشهای پیچیده و محاسبات سنگین دارند. بنابراین، این سرورها معمولا از پردازندههای قوی مانند پردازندههای چند هستهای و پردازندههای با سرعت بالا (مثل Intel Xeon یا AMD EPYC) بهره میبرند تا قادر به پردازش حجم عظیم دادهها در زمان کم باشند.
حافظه (RAM) بسیار بالا
دادههای بیگ دیتا معمولاً به حافظه زیادی نیاز دارند، بنابراین سرورهای اختصاصی برای بیگ دیتا باید حافظه RAM بالایی داشته باشند. این میزان رم میتواند به صد گیگابایت یا حتی بیشتر برسد. این به سرور کمک میکند تا دادهها را سریعتر بارگذاری و پردازش کند.
فضای ذخیرهسازی وسیع
به دلیل حجم بالای دادهها، سرورهای اختصاصی برای بیگ دیتا نیاز به فضای ذخیرهسازی زیادی نیز دارند. این ذخیرهسازی میتواند شامل هارد دیسکهای SSD با ظرفیتهای بالا یا سیستمهای ذخیرهسازی توزیع شده(مثل Hadoop Distributed File System – HDFS) باشد تا دادهها به صورت توزیعشده ذخیره و مدیریت شوند.
شبکه پرسرعت
دادههای بیگ دیتا اغلب به سرعت تولید و منتقل میشوند. بنابراین، سرورهای اختصاصی برای بیگ دیتا نیازمند اتصال شبکه با سرعت بالا هستند تا بتوانند دادهها را با سرعت بالا بین سرورها و دستگاهها منتقل کنند. این سرورها دارای پورتهای 10 گیگابیت یا حتی 40 گیگابیت برای انتقال سریع دادهها هستند.
مقیاسپذیری
سرورهای اختصاصی برای بیگ دیتا باید به راحتی قابلیت مقیاسپذیری داشته باشند، یعنی قادر باشند به تدریج منابع پردازشی، ذخیرهسازی و حافظه بیشتری اضافه کنند. این ویژگی به کاربران کمک میکند تا با افزایش حجم دادهها، به راحتی زیرساخت خود را گسترش دهند.
امنیت بالا
دادههای بیگ دیتا بسیار حساس و مهم هستند. بنابراین، سرورهای اختصاصی باید از ویژگیهای امنیتی بالا مانند رمزگذاری دادهها، مراقبت از دسترسیها و حسابهای کاربری و پشتیبانگیریهای منظم باشند تا از دادهها در برابر تهدیدات و حملات سایبری محافظت کنند.
استفاده از نرمافزارهای تخصصی
برای مدیریت و پردازش دادههای بیگ دیتا، از نرمافزارهای خاصی مانند Apache Hadoop، Spark، NoSQL Databases (مانند MongoDB و Cassandra) و Apache Kafka استفاده میشود. سرورهای اختصاصی برای بیگ دیتا معمولاً به گونهای پیکربندی میشوند که این نرمافزارها به صورت مؤثر روی آنها اجرا شوند.
| ویژگی | سرور اختصاصی معمولی | سرور اختصاصی برای بیگ دیتا |
| عملکرد پردازشی | پردازندههای قوی اما بدون پشتیبانی از پردازش توزیعشده | پردازندههای چند هستهای و بهینهشده برای محاسبات موازی |
| نحوه نوشتن داده | امکان وقفههای کوچک در پردازش دادهها | بدون تأخیر در پردازش اطلاعات |
| نوع ذخیرهسازی | محدود به پایگاه دادههای SQL | پشتیبانی از NoSQL و NewSQL برای مدیریت دادههای بدون ساختار |
| هزینه | ارزانتر به دلیل استفاده از سختافزار معمولی | هزینه بالاتر به دلیل استفاده از سختافزار پیشرفته |
چگونه یک سرور اختصاصی برای بیگ دیتا انتخاب کنیم؟
قبل از خرید سرور ابتدا باید نیازهای کسبوکارتان را بشناسید و بدانید که چه میزان دادهای قرار است پردازش شود تا بتوانید بهترین سرور را انتخاب کنید. از آنجا که سرورهای بیگ دیتا هزینه بیشتری نسبت به سرورهای معمولی دارند، باید یک استراتژی مشخص برای انتخاب سختافزار و نرمافزار داشته باشید. برای اینکه سریعتر بتوانید تصمیم بگیرید، باید به نکات زیر توجه کنید:
زیرساخت توزیعشده یا سرور اختصاصی؟
بسیاری از نرمافزارهای بیگ دیتا روی زیرساختهای توزیعشده اجرا میشوند؛ اما این بدان معنا نیست که همیشه نیاز به چند سرور دارید. در برخی موارد میتوان از یک سرور اختصاصی قدرتمند با تعداد هستههای بالا استفاده کرد، درحالیکه در موارد دیگر ممکن است به کلاستری متشکل از چند سرور کوچکتر در فضای ابری نیاز داشته باشید.
سرور اختصاصی یا کلاستر؟
سرور اختصاصی پرقدرت برای کسبوکارهایی مناسب است که حجم بالایی از داده را پردازش میکنند اما نیاز به توزیع بار پردازش روی چند سرور ندارند. کلاستر نیز برای کسبوکارهایی مناسب است که به زیرساخت توزیعشده و مقیاسپذیر نیاز دارند.
هزینه و نیاز کسبوکار
اینکه یک سرور اختصاصی برای بیگ دیتا انتخاب کنید یا چند سرور کوچک، کاملاً به میزان پردازش مورد نیاز شما، مقیاسپذیری مدنظرتان و بودجهای که در اختیار دارید؛ وابسته است.
| ویژگی | سرورهای تکی (Single Servers) | کلاستر سرور (Clusters) |
| توزیع پردازش | پردازش روی یک سرور واحد | پردازش توزیعشده بین چندین سرور |
| مقیاسپذیری (Scalability) | مقیاسپذیری محدود به توان سختافزاری همان سرور | افزایش مقیاس با افزودن سرورهای جدید |
| تحمل خطا (Redundancy) | پایین، خرابی سرور باعث اختلال میشود | بالا، در صورت خرابی یک سرور، سایر سرورها وظایف آن را بر عهده میگیرند |
| هزینه اولیه | کمتر، زیرا فقط یک سرور نیاز است | بیشتر، به دلیل نیاز به چندین سرور و شبکهبندی |
| پیچیدگی راهاندازی | سادهتر، تنها نیاز به تنظیم یک سرور دارد | نیازمند پیکربندی شبکه، هماهنگی بین سرورها و تنظیم نرمافزارهای توزیعشده |
| کاربرد | مناسب برای پروژههای کوچک | مناسب برای حجم بالای داده و پردازشهای پیچیده |
| انعطافپذیری | محدود به پردازش یک مجموعه داده در هر لحظه | امکان اجرای همزمان چند پروژه بیگ دیتا در یک ابر خصوصی (Private Cloud) |
نرمافزارهای مورد نیاز سرور اختصاصی برای بیگ دیتا
برای مدیریت و تحلیل بیگ دیتا علاوه بر سختافزارهای قدرتمند به مجموعهای از نرمافزارهای پیشرفته هم نیاز است. این نرمافزارها باید بتوانند دادههای حجیم را پردازش، تحلیل و در صورت لزوم بصریسازی کنند. این نرمافزارها بهطورکلی به 3 دسته تقسیم میشوند:
1. نرمافزارهای ذخیرهسازی و پردازش دادهها
این نرمافزارها برای ذخیرهسازی و پردازش دادههای حجیم طراحی شدهاند و امکان بازیابی و تغییر اطلاعات را فراهم میکنند.
- HDFS: یک سیستم فایل توزیع شده است که بخشی از اکوسیستم Hadoop محسوب میشود.
- HBase: یک پایگاه داده توزیع شده است که روی HDFS اجرا میشود. از این پایگاه داده برای ذخیره و پردازش حجم بالایی از دادهها استفاده میشود.
- Hive: یک سیستم انبار داده است که روی Hadoop اجرا میشود و امکان پردازش دادههای HBase و دادههای دیگر را فراهم میکند.
- Cassandra: یک پایگاه داده NoSQL است که از آن برای پردازش دادههای حجیم با مقیاسپذیری بالا استفاده میشود. زبان این پایگاه داده CQL است.
- MongoDB: یک پایگاه داده NoSQL از نوع document-based است که از ویژگیهای مهم آن میتوان به مقیاسپذیری بالا و مدیریت دادههای بدون ساختار اشاره کرد.
- Elasticsearch: یک موتور جستجوی پیشرفته برای مدیریت و ذخیرهسازی دادههای بدون ساختار است که قابلیت جستجوی متن کامل را دارد.
2. نرمافزارهای فید داده و محاسبات
از این دسته از نرمافزارها برای پردازش دادههای ورودی در لحظه استفاده میشود.
- Apache Storm: یک موتور پردازش داده است که از spouts و bolts برای پردازش دادهها بهصورت توزیعشده استفاده میکند.
- Apache Spark: یک فریمورک محاسباتی است که امکان تحلیل دادهها بهصورت توزیعشده را فراهم میکند.
- Logstash: ابزاری برای پردازش و انتقال دادهها است که معمولاً از آن در کنار Elasticsearch و Kibana برای ساخت ELK Stack استفاده میشود.
- Kafka: یک سرویس پردازش و استریمینگ داده است که برای تحلیلهای آنی مورد استفاده قرار میگیرد.
-
بصریسازی و دادهکاوی
از این ابزارها برای نمایش اطلاعات بهصورت گرافیکی و تجزیهوتحلیل دادهها استفاده میشود.
- Tableau: یک نرمافزار بصریسازی داده است که از قابلیتهای آن میتوان به تجزیهوتحلیل هوش تجاری (BI) اشاره کرد.
- Power BI: یک سرویس تحلیل داده از مایکروسافت است که داشبوردهای تعاملی خوبی دارد.
- Grafana: یک اپلیکیشن تحت وب برای تحلیل و بصریسازی دادهها است.
چگونه سرور بیگ دیتا را بهینهسازی کنیم؟
پس از انتخاب سرور اختصاصی برای پردازش دادههای حجیم، باید آن را بهینهسازی کنید تا بهرهوری به حداکثر مقدار ممکن برسد. برخی از مهمترین پارامترهایی که باید برای بهینهسازی سرورهای بیگ دیتا در نظر بگیرید، عبارتاند از:
شبکه پرسرعت
از آنجا که پردازش بیگ دیتا نیازمند انتقال حجم بالایی از اطلاعات است، باید از شبکهای با پهنای باند کافی استفاده کنید. بهتر این است که شبکهای با حداقل سرعت ۱ گیگابیت بر ثانیه انتخاب کنید.
فضای ذخیرهسازی مناسب
فضای ذخیرهسازی باید علاوه بر دادههای اصلی، ظرفیت کافی برای دادههای موقت هم داشته باشد. در انتخاب بین SSD و هارد دیسک معمولی، باید نیازهای کسبوکارتان را در نظر بگیرید. Hadoop و Spark معمولاً با چند درایو بهتر عمل میکنند.
رم کافی (RAM)
هرچه مقدار رم بیشتر باشد، پردازش بیگ دیتا سریعتر انجام میشود. ابزارهایی مانند Apache Spark و Couchbase دادهها را در حافظه نگه میدارند و پردازش میکنند. بهتر است حداقل از یک رم ۶۴ گیگابایتی استفاده کنید.
پردازندههای چند هستهای
ابزارهای تحلیل بیگ دیتا مانند Spark پردازش را در چند رشته (Thread) انجام میدهند. در واقع از هستههای پردازنده بهصورت موازی استفاده میکنند. پردازشگرهایی با حداقل ۸ تا ۱۶ هسته، عملکرد سرور اختصاصی برای بیگ دیتا را بهطور قابلتوجهی ارتقا میدهند.
جمع بندی
سرور اختصاصی برای بیگ دیتا یک راهکار عالی برای ذخیرهسازی و پردازش دادههای حجیم است که با استفاده از سختافزار قدرتمند، پردازش موازی و پشتیبانی از پایگاههای داده پیشرفته، موجب بهینهسازی فرایند پردازش میشود. برای انتخاب سرور اختصاصی یا کلاستر باید نیازهای کسبوکار، مقیاسپذیری و بودجهتان را در نظر بگیرید. برای اینکه سرور اختصاصی عملکرد بهتری داشته باشد، توصیه میشود از شبکههای پرسرعت، فضای ذخیرهسازی مناسب، رم بالا و پردازندههای چند هستهای استفاده کنید. در نهایت، ایجاد یک زیرساخت مناسب و بهینه برای بیگ دیتا میتواند بهرهوری سازمانی را افزایش دهد و تحلیل دادهها را تسریع کند.
سوالات متداول
چگونه یک سرور اختصاصی برای بیگ دیتا انتخاب کنیم؟
برای انتخاب سرور مناسب، باید میزان دادهای که قرار است پردازش شود، نیاز به مقیاسپذیری، نوع پایگاه داده (SQL یا NoSQL) و هزینههای سختافزاری را در نظر بگیرید.
چه نرمافزارهایی برای مدیریت و پردازش بیگ دیتا روی سرور اختصاصی قابلاستفاده هستند؟
نرمافزارهایی مانند Hadoop، Apache Spark، HDFS و پایگاههای داده NoSQL مانند Cassandra و MongoDB برای مدیریت و پردازش دادههای حجیم مناسب هستند.
چگونه میتوان سرور اختصاصی برای بیگ دیتا را بهینهسازی کرد؟
برای بهینهسازی سرور، باید از شبکه پرسرعت (حداقل ۱ گیگابیت بر ثانیه)، فضای ذخیرهسازی مناسب (SSD)، رم کافی (حداقل ۶۴ گیگابایت) و پردازندههای چند هستهای (۸ تا ۱۶ هسته) استفاده کنید.